
Sieci
Jak zmienić hasło do Wi-Fi i zabezpieczyć swoją sieć przed nieautoryzowanym dostępem
Zmiana hasła do Wi-Fi to kluczowy krok w zabezpieczeniu sieci. Dowiedz się, jak skutecznie zmienić hasło do Wi-Fi i ochronić swoje połączenie.
Jak zmienić hasło do Wi-Fi i zabezpieczyć swoją sieć przed nieautoryzowanym dostępem
Zmiana hasła do Wi-Fi to kluczowy krok w zabezpieczeniu sieci. Dowiedz się, jak skutecznie zmienić hasło do Wi-Fi i ochronić swoje połączenie.

Jak wypełnić wniosek o określenie warunków przyłączenia do sieci gazowej bez błędów
Dowiedz się, jak wypełnić wniosek o określenie warunków przyłączenia do sieci gazowej, unikając błędów i opóźnień w procesie przyłączenia.

Co oznacza R przy zasięgu? Dowiedz się, co to dla Twojego telefonu
Zastanawiasz się, co oznacza R przy zasięgu? Dowiedz się, jak roaming wpływa na Twoje połączenia i jakie ma znaczenie dla Twojego telefonu.
Portal ProgramowanieObiektowe.pl to miejsce stworzone przez zespół zapalonych autorów, którzy dzielą się swoją wiedzą i doświadczeniem w obszarze programowania obiektowego. Nasz blog oferuje szeroki wachlarz artykułów, tutoriali oraz narzędzi, które pomogą Ci rozwijać umiejętności programistyczne. Niezależnie od tego, czy jesteś początkującym programistą, czy doświadczonym profesjonalistą, znajdziesz tu cenne zasoby i inspiracje. Zachęcamy do eksploracji naszych treści i dołączenia do naszej społeczności, gdzie wspólnie odkrywamy tajniki nowoczesnych technologii.

Zmień hasło wifi na telefonie w prosty sposób. Dowiedz się, jak uzyskać dostęp do ustawień i zabezpieczyć swoją sieć Wi-Fi na Androidzie i iOS.
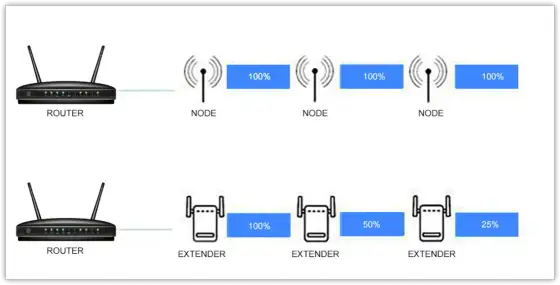
Zwiększ zasięg Wi-Fi domowym sposobem bez dużych kosztów. Sprawdź skuteczne metody, które poprawią jakość sygnału w Twoim domu.

Naucz się, jak przesłać zdjęcia z aparatu Sony na telefon przez Wi-Fi w kilku prostych krokach. Szybko i łatwo ciesz się swoimi zdjęciami na smartfonie!

Dowiedz się, kiedy sztuczna inteligencja zastąpi programistów oraz jakie zmiany czekają branżę IT w przyszłości. Przeczytaj o współpracy człowieka z AI!
Czy VPN jest darmowy? Sprawdź, jakie pułapki i ryzyka wiążą się z korzystaniem z bezpłatnych usług VPN, aby chronić swoją prywatność online.

Zastanawiasz się, jaki zasięg ma CB radio? Dowiedz się, jakie czynniki wpływają na odległość i jak maksymalizować jego efektywność.






Skonfiguruj Xiaomi Mi Robot Vacuum Mop Pro z Wi-Fi w kilku prostych krokach. Dowiedz się, jak połączyć odkurzacz z siecią i ciesz się jego inteligentnymi funkcjami.
Zmiana Wi-Fi w drukarce Epson jest prosta. Dowiedz się, jak zmienić Wi-Fi w drukarce Epson i uniknąć problemów z połączeniem.

Ile kosztuje VPN? Sprawdź ceny subskrypcji, oszczędności przy długoterminowych planach i oferty, które pomogą Ci zaoszczędzić na usługach VPN.

Zdalne sterowanie piecem z aplikacją to komfort i oszczędności. Wybierz sterownik WiFi do pieca CO i ciesz się optymalnym ogrzewaniem w swoim domu.

Poznaj najlepsze narzędzia, które wykorzystują sztuczną inteligencję do pisania. Dowiedz się, jak nazywa się sztuczna inteligencja do pisania i jak może Ci pomóc.

Odkryj, jak oglądać filmy VR na telefonie i ciesz się pełną immersją. Sprawdź najlepsze aplikacje i techniki, aby w pełni wykorzystać swoje urządzenie.

Zastanawiasz się, jaka jest najlepsza sztuczna inteligencja? Sprawdź najpopularniejsze narzędzia AI i wybierz idealne rozwiązanie dla siebie!

Zarabiaj na sztucznej inteligencji dzięki sprawdzonym metodom, takim jak tworzenie aplikacji, analiza danych czy chatboty. Dowiedz się więcej!


Naucz się, jak dodać tło HTML w prosty sposób i uniknąć typowych błędów. Odkryj skuteczne metody i najlepsze praktyki dla estetyki strony.

Dowiedz się, jak ustawić szerokość strony HTML, wykorzystując różne metody i unikając typowych błędów w designie, aby poprawić responsywność i estetykę.

Wybierz między CMS a HTML i dowiedz się, który z tych systemów oszczędzi czas i pieniądze na Twojej stronie internetowej.
Naucz się, jak przesunąć obrazek w HTML, wykorzystując proste metody CSS i JavaScript, aby osiągnąć idealne położenie na swojej stronie.



Wzmocnij Wi-Fi w domu i pozbądź się problemów z zasięgiem. Sprawdź skuteczne metody na lepszy zasięg i stabilność połączenia internetowego.
Znajdź hasło do wifi na komputerze w prosty sposób. Sprawdź metody dla połączenia i offline, aby szybko uzyskać dostęp do swojej sieci.

Zobacz, gdzie jest wykorzystywana sztuczna inteligencja w przemyśle, medycynie i codziennym życiu. Poznaj jej wpływ na nasze decyzje i komfort.

Zobacz, jak wstawić zdjęcie na tło w HTML w prosty sposób. Praktyczne przykłady i porady, które poprawią estetykę Twojej strony internetowej.